> ## Documentation Index
> Fetch the complete documentation index at: https://wb-21fd5541-docs-hivemind-launch.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
> W&B を Stable Baselines3 と統合して、強化学習の実験をトラッキングし、トレーニングのパフォーマンスをログします。
# Stable Baselines 3 PyTorch
[Stable Baselines 3](https://github.com/DLR-RM/stable-baselines3) (SB3) は、PyTorch で実装された信頼性の高い強化学習アルゴリズム群です。W\&B の SB3 インテグレーションでは、次のことができます。
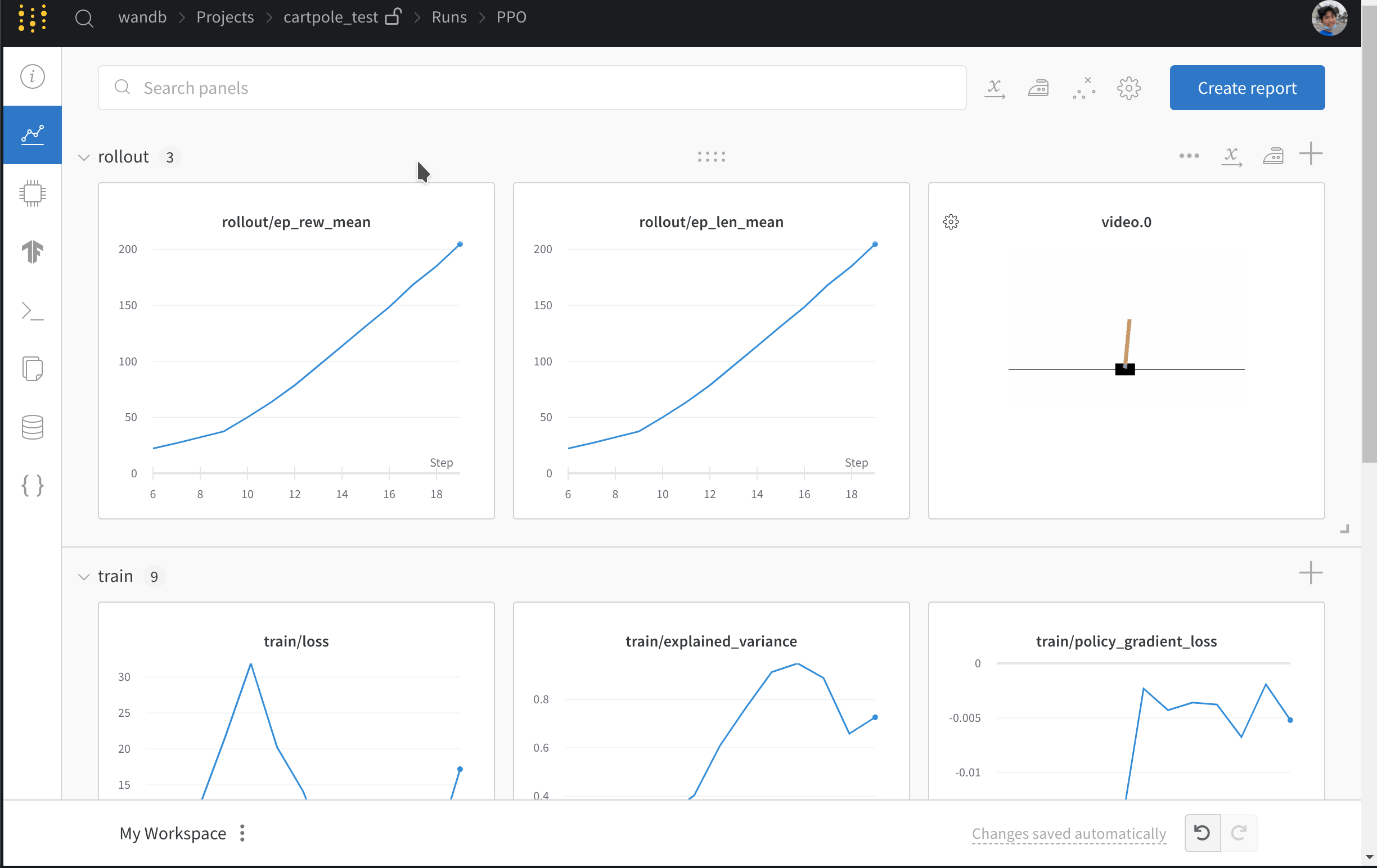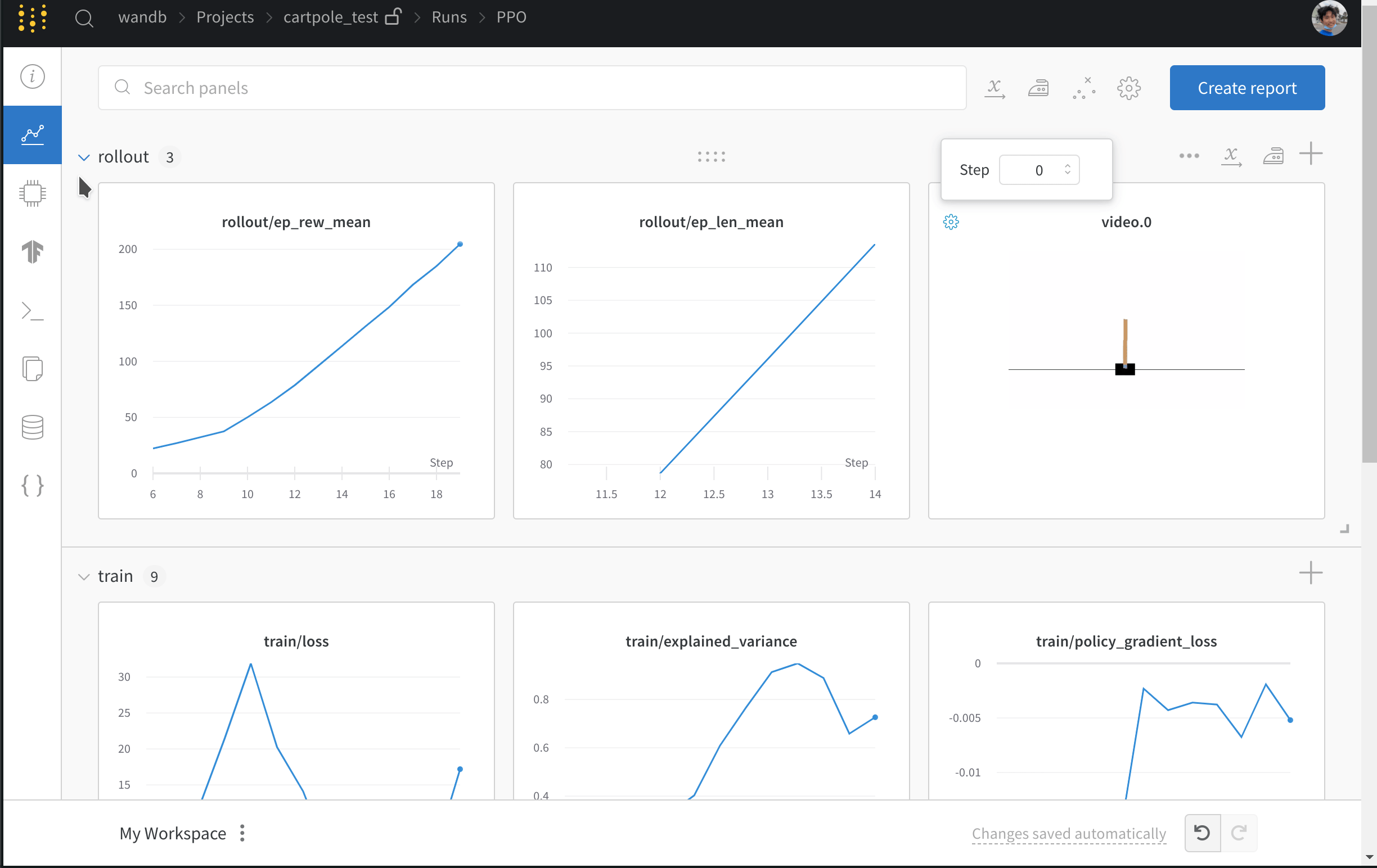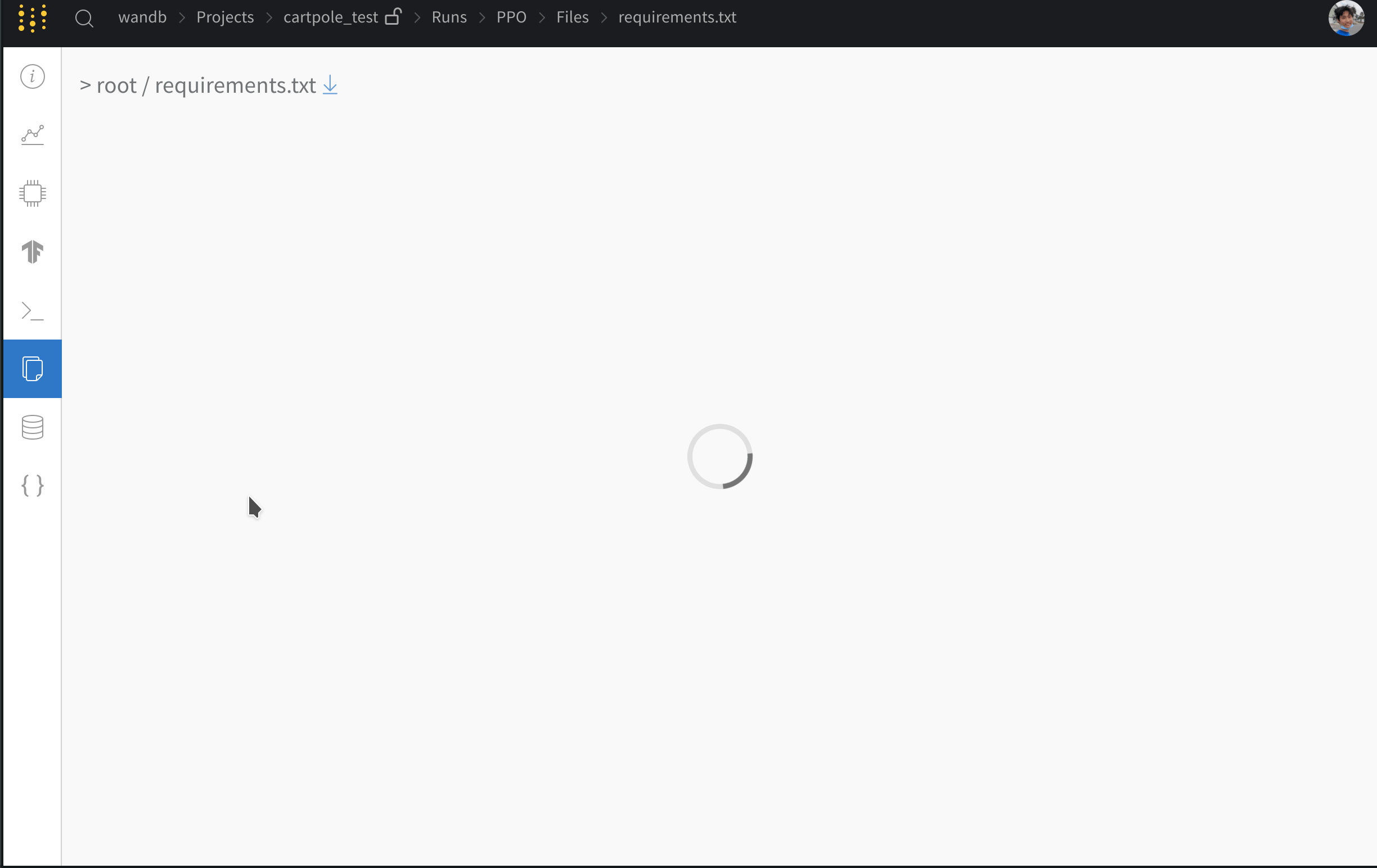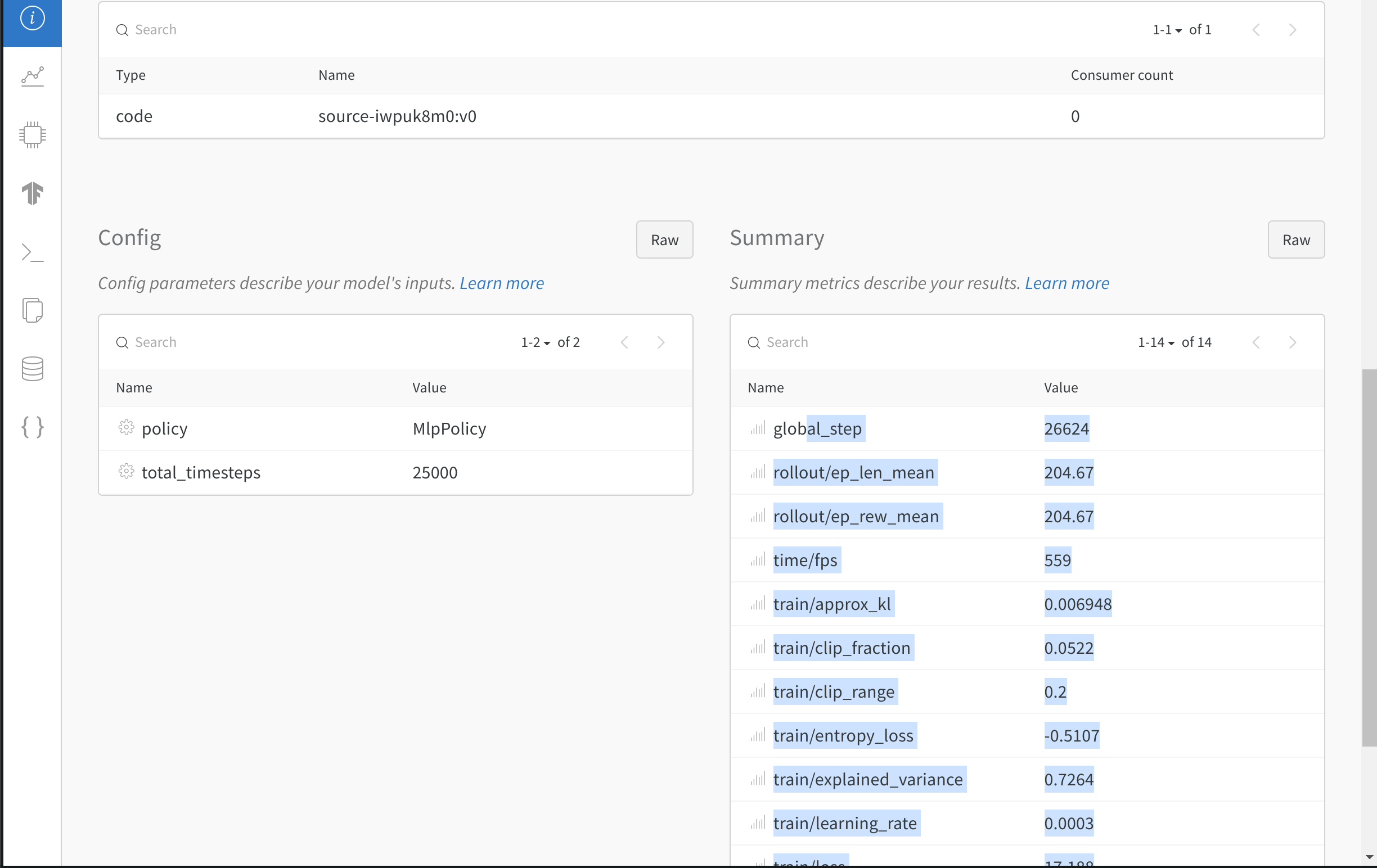
* 損失やエピソードごとのリターンなどのメトリクスを記録します。
* ゲームをプレイするエージェントの動画をアップロードします。
* トレーニング済みモデルを保存します。
* モデルのハイパーパラメーターをログします。
* モデルの勾配ヒストグラムをログします。
[SB3 のトレーニング run の例](https://wandb.ai/wandb/sb3/runs/1jyr6z10)をご覧ください。
## SB3 Experimentsをログする
```python theme={null}
from wandb.integration.sb3 import WandbCallback
model.learn(..., callback=WandbCallback())
```
## WandbCallback の引数
| 引数 | 用途 |
| :------------------- | :------------------------------------------------ |
| `verbose` | sb3 出力の詳細レベル |
| `model_save_path` | モデルを保存するフォルダーのパス。デフォルト値は `None` で、その場合モデルはログされません |
| `model_save_freq` | モデルを保存する頻度 |
| `gradient_save_freq` | 勾配をログする頻度。デフォルト値は 0 のため、勾配はログされません |
## 基本的な例
W\&B SB3 インテグレーションでは、TensorBoard から出力されるログを使用してメトリクスをログします
```python theme={null}
import gym
from stable_baselines3 import PPO
from stable_baselines3.common.monitor import Monitor
from stable_baselines3.common.vec_env import DummyVecEnv, VecVideoRecorder
import wandb
from wandb.integration.sb3 import WandbCallback
config = {
"policy_type": "MlpPolicy",
"total_timesteps": 25000,
"env_name": "CartPole-v1",
}
run = wandb.init(
project="sb3",
config=config,
sync_tensorboard=True, # sb3のtensorboardメトリクスを自動アップロード
monitor_gym=True, # エージェントがゲームをプレイする動画を自動アップロード
save_code=True, # 任意
)
def make_env():
env = gym.make(config["env_name"])
env = Monitor(env) # リターンなどの統計を記録
return env
env = DummyVecEnv([make_env])
env = VecVideoRecorder(
env,
f"videos/{run.id}",
record_video_trigger=lambda x: x % 2000 == 0,
video_length=200,
)
model = PPO(config["policy_type"], env, verbose=1, tensorboard_log=f"runs/{run.id}")
model.learn(
total_timesteps=config["total_timesteps"],
callback=WandbCallback(
gradient_save_freq=100,
model_save_path=f"models/{run.id}",
verbose=2,
),
)
run.finish()
```